【Python】SEO対策に使うため上位100サイトの履歴を貯めていくツールを作ってみる
前回ではSEO対策用として、コマンドプロンプト上で上位100サイトを閲覧できるツールを作成いたしました。
これがあれば簡単に、キーワードに対してどのようなサイトが上位を占めているのかを閲覧することができるようになります。
今回はその発展形として、定期的にpythonのスクリプトを回し、上位100サイトの履歴を記録していくツールを作成してみます。
【Python】SEO対策(時系列比較)に使うため上位100サイトの履歴を貯めていくツールを作ってみる
やってみたこと
- Excelファイルを一つ用意して、そこに検索のためのキーワードを記入する。
- Excelファイルのキーワードをもとに、googleの検索結果の上位100サイトを抽出して、CSVに保存していく。
- データを貯める理由はSEO対策を的確にかつ、早めにおこなえるようにするため。最終的には時系列比較をしていきたいと思っているので。
結果
- 上位100サイトのデータがCSVに保存できている。
- 時系列比較をするためには、数日間はスクリプトを回して、データを貯めていく必要がある。
- ターゲットとするキーワードが多くなると、その分CSVファイルだと容量がすぐ緊迫してきそうなので、データベースにデータを貯めたほうが間違いなく良い!
$ python grc_test.py

出力結果
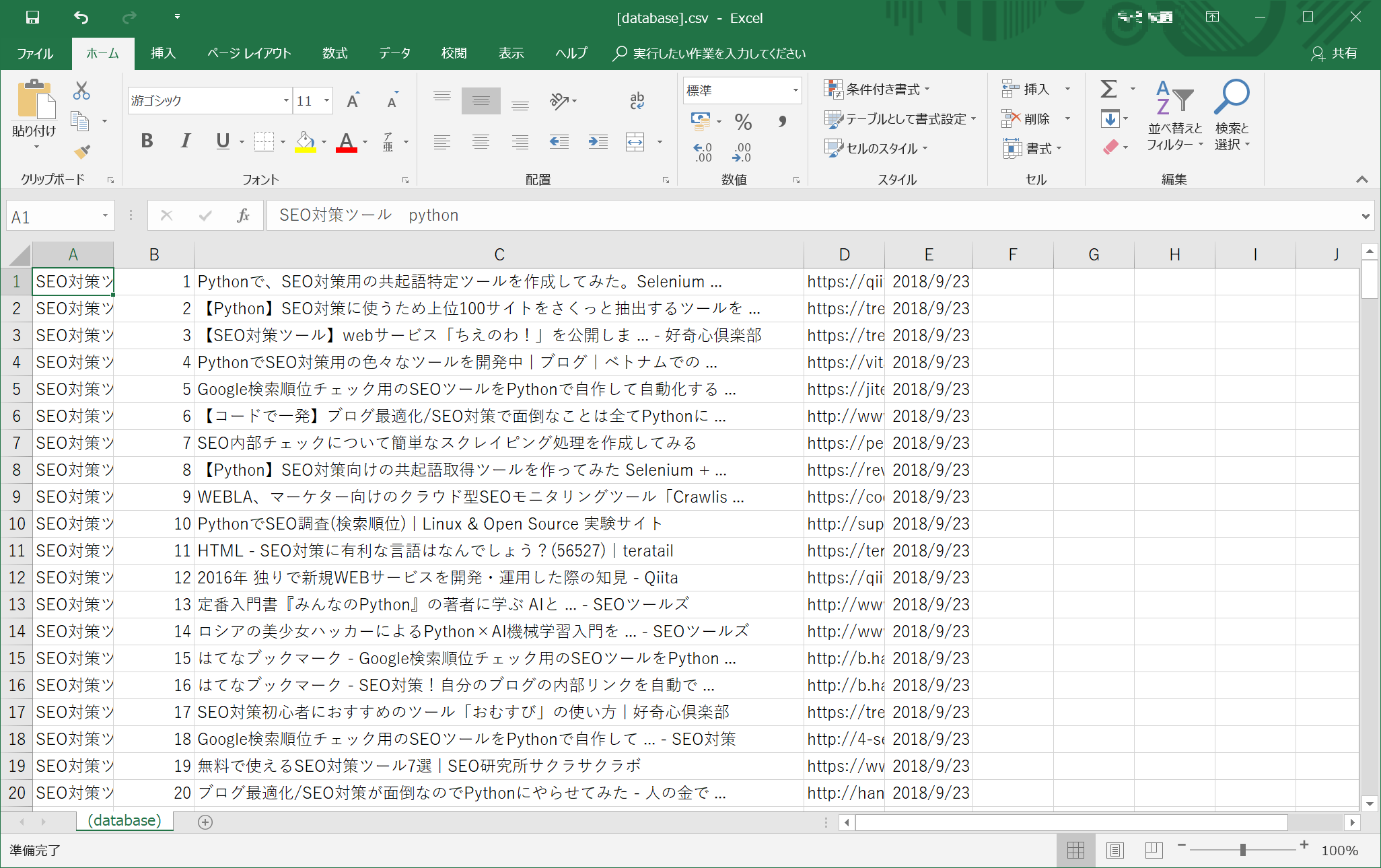
pythonスクリプトの名前は「grc_test.py」としています。(挙動がそのまんまGRCっぽいため)
うまくCSVに追加できていますね!!
初回のみ、CSVを自動で生成し(【database】csv)、それ以降は、上書きしていきます。
実行時の日時が入るので、これで念願の時系列比較ができるようになりそうです。
実装
- requests
- beautifulsoup4
- csv
- datetime
- pandas
- time
import requests
import bs4
import csv
import datetime
import pandas as pd
from time import sleep
#出力データ
output_data = []
# output_data.append(['クエリ','検索順位', 'サイトtitle', 'サイトURL', '日付'])
today=datetime.date.today()#今日の日付
#検索順位取得処理
def search_url_google(search_url_keyword):
if search_url_keyword and search_url_keyword.strip():
#Google検索の実施
search_url = 'https://www.google.co.jp/search?hl=ja&num=100&filter=0&q=' + search_url_keyword
print("[INFO]Googleにアクセスしました")
res_google = requests.get(search_url)
print("[INFO]検索結果の取得に成功しました。")
print("-----------------------------------------------------------------------")
res_google.raise_for_status()
#BeautifulSoupで掲載サイトのURLを取得
bs4_google = bs4.BeautifulSoup(res_google.text, 'html.parser')
link_google = bs4_google.select('div > h3.r > a')
for i in range(len(link_google)):
#なんか変な文字が入るので除く
site_url = link_google[i].get('href').split('&sa=U&')[0].replace('/url?q=', '')
site_title=bs4_google.select('div > h3.r > a')[i].text#textで中身抽出。stringでもいいけどなぜかnoneが返る
if 'https://' in site_url or 'http://' in site_url:
#サイトの内容を解析
try:
#print("[{}位:「{}」,URL「{}」]".format(i+1,site_title,site_url))
rank = i+1
title = site_title
URL = site_url
output_data_new = search_url_keyword, rank, title, URL, today
output_data.append(output_data_new)
except:
continue
#CSVに書き出し
def csv_write():
csv_file = open('[database].csv', 'a', encoding="utf_8_sig")
csv_writer = csv.writer(csv_file, lineterminator='\n')
csv_writer.writerows(output_data)
csv_file.close()
#Excelファイル読み込み
file = pd.ExcelFile('調査URLクエリ設定先.xlsx', encoding='utf8')
sheet_def = file.parse('Sheet1', header=None)
sheet_def = sheet_def[2:]
# 行ごとに処理
for i, row in sheet_def.iterrows():
print('検索ワード:{}'.format(sheet_def.iat[i-2,1]))
search_url_google(sheet_def.iat[i-2,1])
sleep(2)
csv_write()
print("ok")#終わり
[adsense][adsense]
実行前に、pythonスクリプトと同じフォルダへエクセルファイルを用意してください
今回は複数のキーワードの検索結果を一括で抽出したかったので、キーワードを保存するファイルを別途用意しています。
ファイル名は「調査URLクエリ設定先.xlsx」としています。シート名は「Sheet1」とします。
変える場合はコードもそれに合わせて書き換えてください。
中身は以下と同じにしてください。
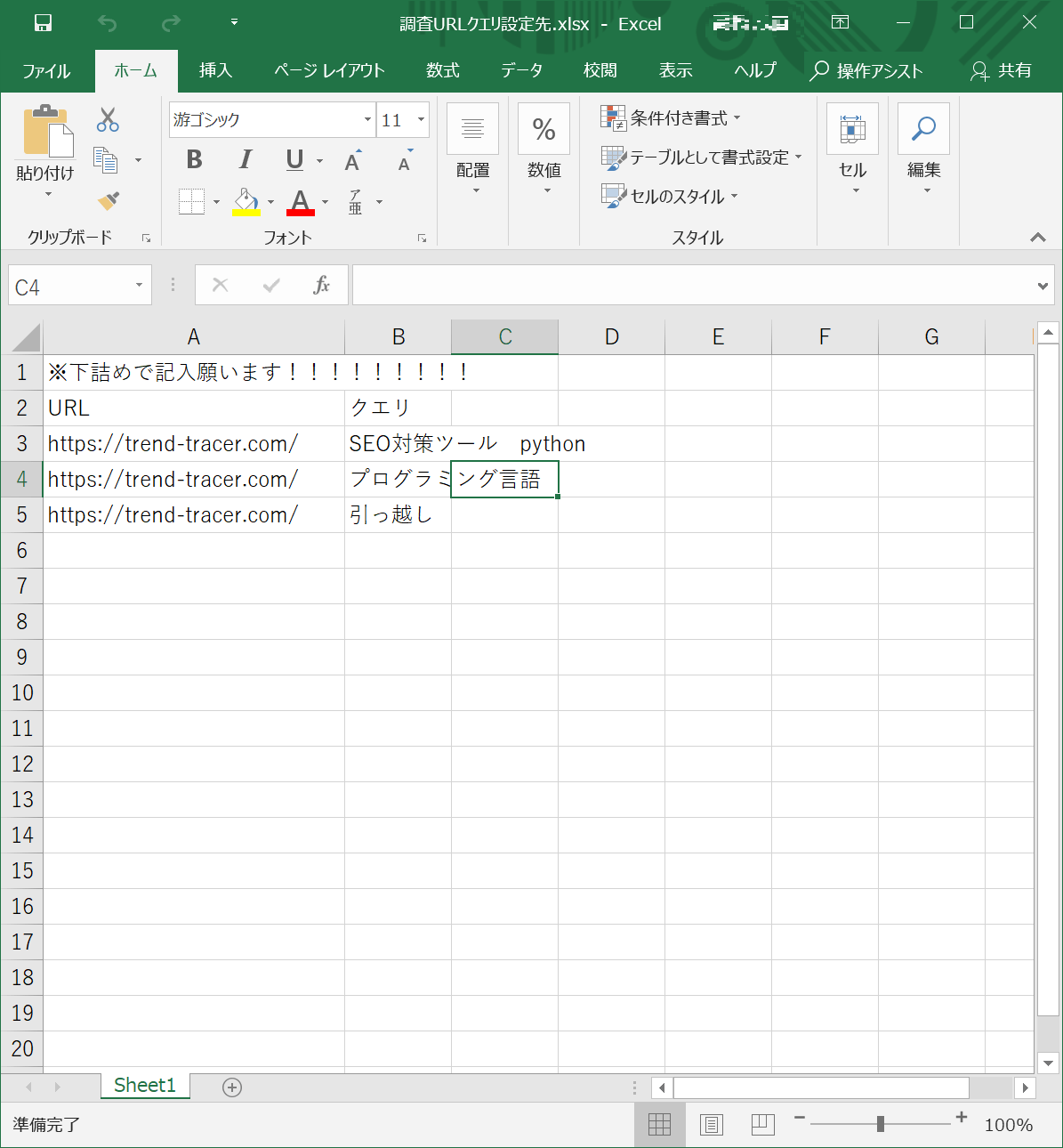
具体的には3行目からURLとクエリ(キーワード)を記述するようにしておいてください。
URLは今回使っていません。
ですが、今後はこのURL(ドメイン)のものが何位なのかを返すこともできるようなスクリプトにしていけると思います。
作成したスクリプトを定期的に自動実行。スクリプトをexeファイル化してタスクスケジューラで回します。
EXEファイル化にはpyinstallerを使おうと思いましたが・・・エラーでEXEファイル化できず仕舞い・・・
スクリプトも作ったし、あとはこれを勝手に動かしてもらうようにするだけだーと意気込んでpyinstallerでEXEファイル化を試みました。
早速実行すると。。。
$pyinstaeer grc_test.py --onefile --noconsole
・・・
・・
・
RecursionError: maximum recursion depth exceeded
「RecursionError: maximum recursion depth exceeded」となり、EXEファイルが生成されませんでした。調べてみると再帰させすぎが原因らしく、解決するためにはSpecいじれ(?)との回答。
ここまでいくと流石に内容がソレてしまいそうなので、今回自動実行までいけませんでしたという結論になってしまい申し訳ございません。
今後としては、このエラーを解消し、EXEファイル化したあと、タスクスケジューラ(Windows)に登録して、定期的にスクリプトを実行する流れになります。
pytinstaller以外にもEXEファイル化するライブラリはありそうですが、早めに解消していきたいです。
なにかお知恵がありましたら是非教えてください(twiiterまで)
最後に
さて、前回作成したスクリプトでは、コマンドラインだけで完結していましたが。今回は「Excelの読み込み」「CSVへの書き出し」までおこなえるようになりました。
pythonは触り始めたばかりですが、ライブラリが豊富でマニュアルも多いので、楽しみながら学んでいます。
CSVに保存していますが、検索すべきキーワードが増えるとデータ量がすぐ大きくなってしそうな雰囲気です。
やはりデータはデータベースに入れて、分析なりを進めたほうが無難でしょう。
今後はmysqlの導入と、ついに時系列比較とアラート機能を自動化していきたいと思います。
とはいえデータ量が少なくても時系列比較なりアラート機能は作成できるので、データベースの実装とどちらを優先させるかは悩みどころとします。
そのあたりも実装できたらエントリしたいとも思います(時期は未定)
以上です。
読んでいただきありがとうございます。