Google ColabでSearch Console APIを使ってデータを取得する方法の備忘録(2023年v3版)
SEOを進める上で、Search Consoleは必須のツールですがブラウザのサーチコンソールから取得できるデータ数が少ない(1000個)ことと、pandasなどを使って分析したいと思った時にいちいちcsvにしてアップロードしてなど手間がかかるためAPIを使おうと思いました。
色々調べてみた結果、なかなかGCP(Google Cloud Platform)の設定から取得するためのコードを一気通貫で解説しているページが少なかったので備忘録として残しておこうと思います。
作業全体の流れ
Google ColabでSearch Console APIを使うための手順としては以下の通り
GCP(Google Cloud Platform)で新規プロジェクトを作成
↓
Oauthに同意する
↓
認証情報からサービスアカウントを作成する
↓
サービスアカウントキーをjsonで作成する
↓
サーチコンソールの設定画面で作成したサービスアカウントに権限を付与する
↓
Colabにアカウントキーのjsonをアップロード
↓
Colab でデータ取得用のコードを実行する
GCP(Google Cloud Platform)側の設定
ログインをしたら新しいプロジェクトを作成します。
プロジェクトを新規作成
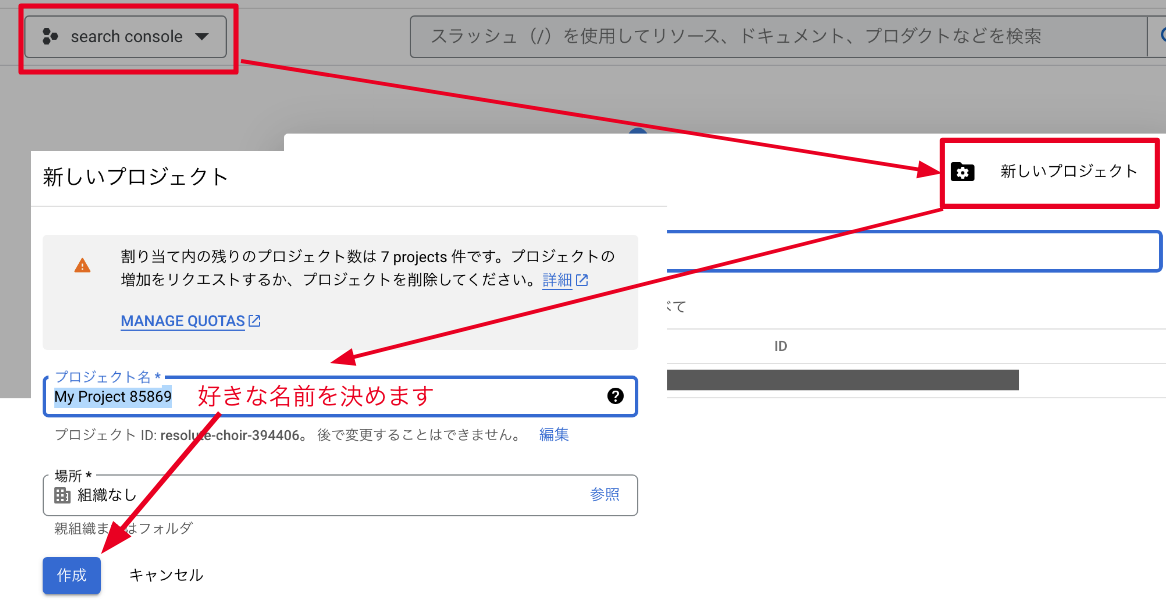
新しいプロジェクトを作成します。
プロジェクト名は自由に決められますが、Search Console APIを使うものであることがわかるような命名にしておくといいと思います。
Search Console APIの有効化
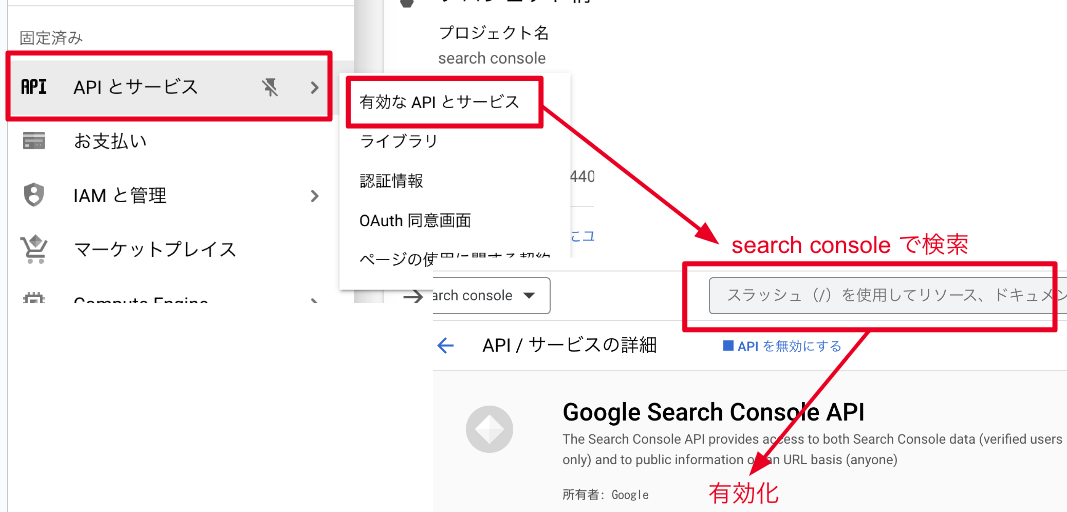
プロジェクトを作成したらSearch Console APIを有効化します。
これをしないとSearch Console APIを利用することはできません。
サービスアカウントキーの作成
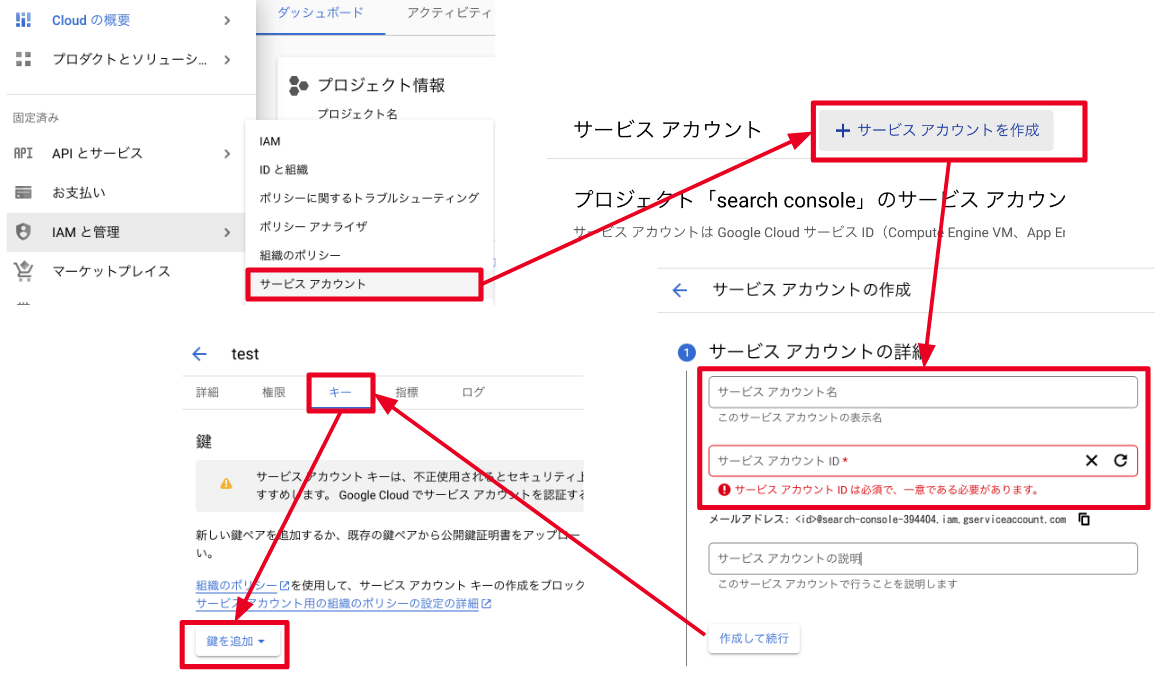
次にサービスアカウントを作成します。
サービスアカウント名とIDは自由に決めることが可能です。
あとでいくらでも確認できるのでパッと決めて次にいきましょう。
秘密鍵をPCに保存する

JSON(推奨)を選択して作成するとファイルを保存するかどうか尋ねられます。
自分がわかる場所に保存をすればOKです。
サーチコンソールにログインして、サービスアカウントに権限を付与する
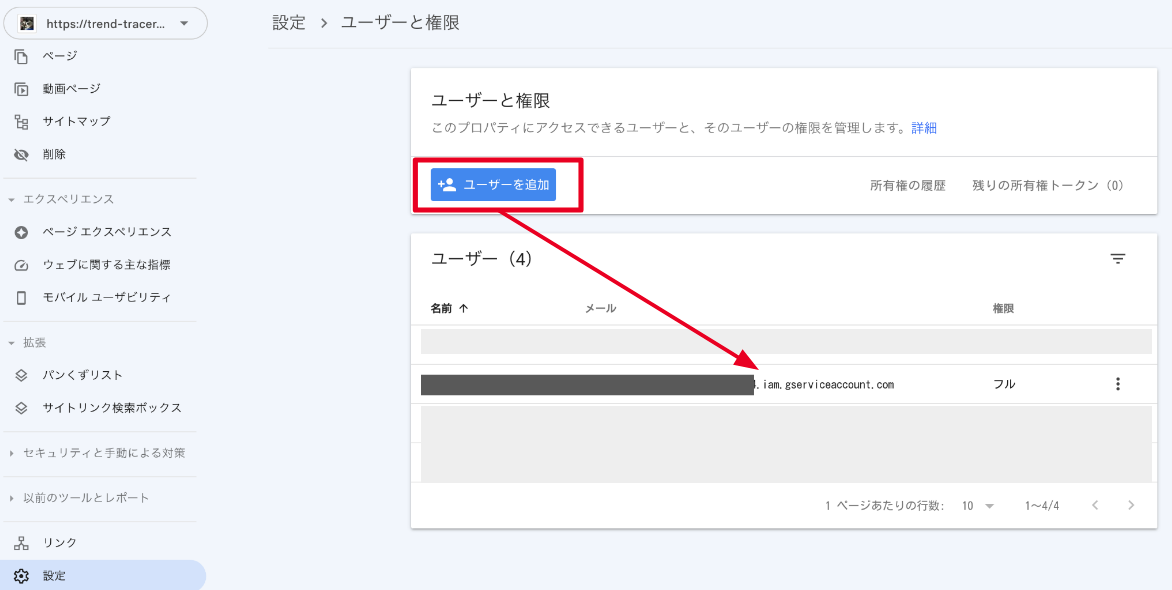
一旦GCPから離れ、サーチコンソールの設定画面にいきます。
「ユーザーと権限」から「ユーザーを追加」を押して、先ほど作成したサービスアカウント(~~iam.gserviceaccount.com)を登録します。
権限は「フル」を指定しておきます。
Google Colabでコードを実行する
ここまできて、やっとコードを実行できます。
参考にしたサイト様は以下のものです。
サンプルコード
# ライブラリをインポート
from google.oauth2 import service_account
from googleapiclient.discovery import build
import pandas as pd
from pandas import DataFrame
from google.colab import files
from google.colab import drive
from datetime import datetime, date, timedelta
from oauth2client.service_account import ServiceAccountCredentials# 認証ファイルをアップロード
uploaded = files.upload()
# アップロードした認証ファイル名を指定
KEY_FILE = 'search-console-json.json' # Replace with your key file## サーチコンソールへのアクセス設定を行う
SCOPES = ['https://www.googleapis.com/auth/webmasters.readonly'] ## 固定設定
KEY_FILE_LOCATION = '*****************.json' ## 自分のgoogle search console上で作成したjsonの認証情報を設定する
credentials = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION, SCOPES)
webmasters = build('webmasters', 'v3', credentials=credentials)
domain = 'https://trend-tracer.com/' ## 自分のgoogle search consoleに登録してあるサイトのURL
dimensions = ['query', 'page']
## 取得データは直近90日分に絞る
today = datetime.today()
startDate = (today - timedelta(days=90)).strftime('%Y-%m-%d') ## 実行日の90日前を指定
endDate = today.strftime('%Y-%m-%d') ## データ取得終了日は処理日を指定
rowLimit = 100 # 取得レコード数の最大値を設定
body = {
'startDate': startDate,
'endDate': endDate,
'dimensions': dimensions,
'rowLimit': rowLimit
}
## ここでデータ取得
response = webmasters.searchanalytics().query(siteUrl=domain, body=body).execute()
df = pd.json_normalize(response['rows'])
## 取得したデータの整形
for i, d in enumerate(dimensions):
df[d] = df['keys'].apply(lambda x: x[i])
## google search consoleの3ヶ月の平均掲載順位を取得
df_positonMarge = df.loc[df.groupby('page')['position'].idxmin()] ## pageでgroupbyした結果で最もpositionが小さい値を取得
print(df_positonMarge["position"].mean().round(2))
df