【Python】tacotron2を使って音声合成をローカル環境で試した時の備忘録
Pythonを使って機械学習を実践してみようと思い、tacotron2という音声合成用のアルゴリズムを使って音声学習をおこなう、自分の好きな声で、好きな文章をしゃべってもらうことができるとのこと。
面白そうなので早速試してみたのですが、色々とエラーがでてすぐに動かすことはできなかったので備忘録としておこなったことをまとめていこうと思います。
最終的に動くようにはなったのですが、個々人の環境によって出るエラーは様々だと思います。
もしも動かない場合はTwitterのDMなりで相談いただければと思います。
https://github.com/NVIDIA/tacotron2
- 1. NVIDIA/tacotron2とは
- 2. 仮想環境は絶対用意する
- 3. 開発環境
- 4. 事前準備
- 5. tacotron2を動かすための環境構築の手順
- 6. 5.apexをインストール
- 7. tacotron2の学習の実行(train.py)
- 8. 遭遇したエラーの一覧と対処に関するメモ
- 8.1. エラー:No module named 'tensorboard’ もしくは’tensorflow’
- 8.2. guvectorize() missing 1 required positional argument: 'signature’
- 8.3. エラー:HDF5 library version mismatched error
- 8.4. エラー:no module named typing_extensions
- 8.5. エラー:future feature annotations is not defined
- 8.6. エラー:’CacheManager’ object has no attribute 'cachedir’
- 8.7. エラー:No module named 'numba.decorators’
- 8.8. エラー:guvectorize() missing 1 required positional argument: 'signature’
- 8.9. エラー:No module named 'numpy.testing.decorators’
- 8.10. module 'tensorflow’ has no attribute 'contrib’
- 8.11. エラー:RuntimeError: CUDA out of memory. tacotron
- 8.12. Downgrade the protobuf package to 3.20.x or lower
- 9. 推論
- 10. まとめ
- 11. 参考記事
NVIDIA/tacotron2とは

Tacotoron2(タコトロンツー)とはGoogleが開発したアルゴリズムのことです。
詳しい論文内容は以下のページで解説されているのでご参考ください。
処理の順番としては「テンソルへの割り当て(前処理)>折り畳みネットワーク(3層)>でコード(2層ニューラルネットワークに通す)>ポスト」という手順らしいですが、詳しいことは正直さっぱり。
追々仕組みは理解するとして、まずは動かせるようになることを最優先とします。
仮想環境は絶対用意する
tacotron2を動かす際に、仮想環境は絶対に用意しましょう。
私はAnacondaで仮想環境を用意しました。
今回動かしてみて思ったことは、tacotoron2用を動かす環境と、推論用に使う環境を分けたほうがいいということです。
特にライブラリ周りでコンフリクトだったり、Pythonのバージョンだったりでエラーが滅茶苦茶吐かれたので苦労しました。
開発環境
- Windows 11
- GPU(NVIDIA Ge Force RTX 2070 SUPER)
事前準備
tacotron2を実行する前におこなうべきことは以下の3点です
- 「Japanese Single Speaker Speech Dataset」をダウンロードしておく
- 「NVIDIA/tacotron2」用に変換(スクリプトの実行)
- 「Tacotron2モデル(Google drive)」と「WaveGlowモデル(Google drive)」をダウンロードしておく
「Japanese Single Speaker Speech Dataset」のダウンロード
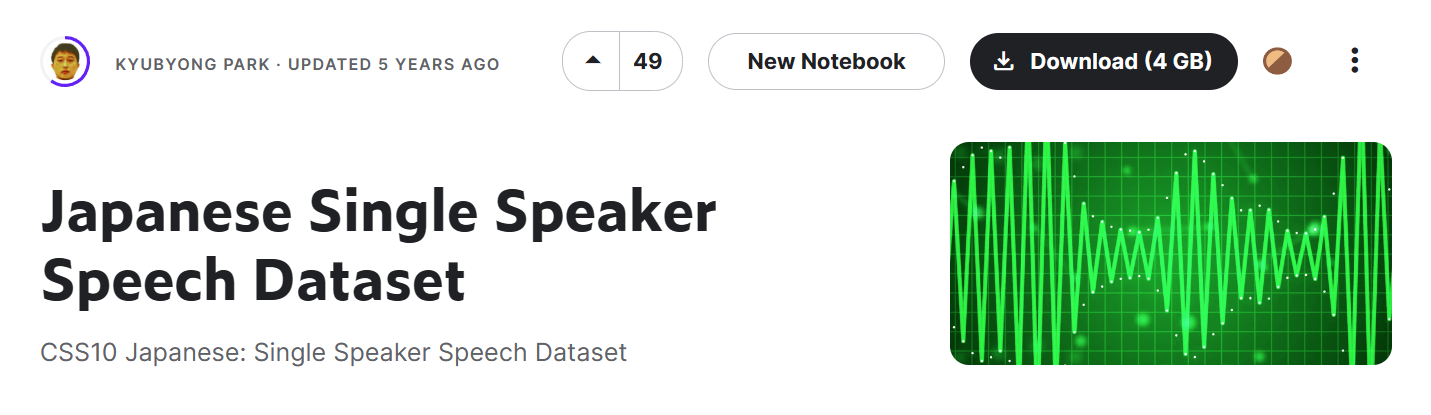
公式サイトからDownloadします。全部で4GBあるので完了まで待ちましょう。
解凍して中を見てみると、日本語で文章を読み上げているwavファイルとtranscript.txtが含まれています。
transcript.txtにはwavファイル内で読み上げられている文章が入っています。
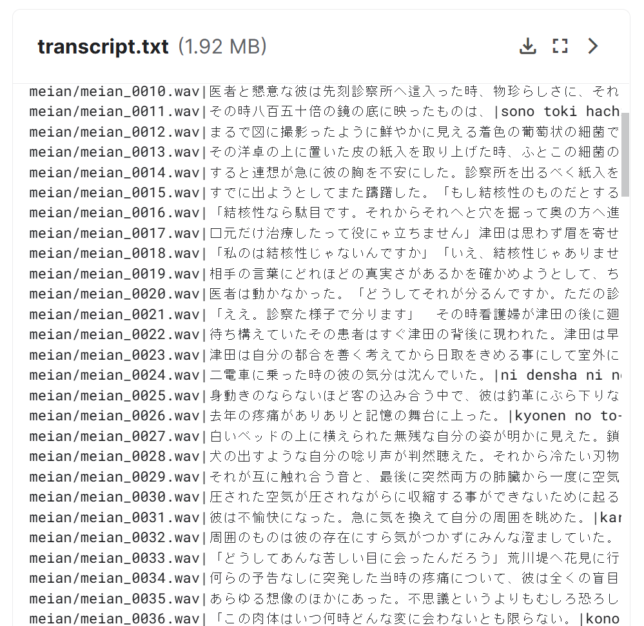
「NVIDIA/tacotron2」用に変換(スクリプトの実行)
import os
# transcript.txtの変換
in_path = 'archive/transcript.txt'
out_path = 'filelists/transcript.txt'
output = []
nums = ['一', '二', '三', '四', '五', '六', '七', '八', '九', '十', '百', '章おわり。']
with open(in_path) as f:
lines = f.readlines()
for line in lines:
strs = line.split('|')
flag = False
for num in nums:
if strs[1].startswith(num):
print(strs[0])
flag = True
break
if flag:
continue
if len(strs[2]) < 10:
continue
strs[2] = strs[2].replace('、',',')
strs[2] = strs[2].replace('。','.')
strs[2] = strs[2].replace('――','')
strs[2] = strs[2].replace('?','')
strs[2] = strs[2].replace('!','')
strs[2] = strs[2].replace(' ','')
output.append(strs[0]+'|'+strs[2]+'\n')
with open(out_path, 'w') as f:
f.writelines(output)https://note.com/npaka/n/n2a91c3ca9f34 より引用
tacotron2は日本語のひらがな、漢字に対応していないので、発音をアルファベット方式にしたものに変換します。
pyファイルの作成場所とin_pathとout_pathはよしなに変更しておきます。

データセットを学習データと検証データにわける
参考サイトではheadとtailというコマンドでテキストファイルを分割していますが、Windwosの場合headとtailコマンドはありません。
なのでこちらの記事を参考にGet-contenで代用してください。
linuxの場合
head -n 6500 filelists/transcript.txt > filelists/transcript_train.txt
tail -n 85 filelists/transcript.txt > filelists/transcript_val.txt
Windowsの場合
Get-Content "filelists/transcript.txt" | Select-Object -first 6500 | Out-File "filelists/transcript_train.txt"
Get-Content "filelists/transcript.txt" | Select-Object -last 85 | Out-File "filelists/transcript_val.txt"「Japanese Single Speaker Speech Dataset」のwavファイルを16ビットに変換する
# 事前実行
# $ pip install librosa==0.8.0
# $ pip install pysoundfile==0.9.0.post1
import os
import librosa
import soundfile as sf
# サンプリングビットの変換
in_path = 'ダウンロード/archive/meian/'
out_path = 'ダウンロード/filelists/meian/'#事前にmeianというフォルダを作っておく
filenames = os.listdir(in_path)
for filename in filenames:
print(out_path+filename)
y, sr = librosa.core.load(in_path+filename, sr=22050, mono=True) # 22050Hz、モノラルで読み込み
sf.write(out_path+filename, y, sr, subtype="PCM_16") #16bitで書き込み
#実行後の完成したmeianフォルダをtacotron2フォルダの配下に移動しておきます「Tacotron2モデル(Google drive)」と「WaveGlowモデル(Google drive)」をダウンロード
「Tacotron2モデル(Google drive)」と「WaveGlowモデル(Google drive)」をダウンロードします。
これはtacotron2のtrain.pyを実行するのに使用します。
そのため、tacotron2のフォルダ配下に置いておきます。
tacotron2を動かすための環境構築の手順
進め方は基本的にtacotron2のgithubと以下のページを参考にさせていただきました。
NVIDIA/tacotron2 で日本語の音声合成を試す (1) - 事始め
参考サイトではGoogle Colabを使っていますが、「TensorFlow 1.X」への切り替えが最近Colabでできなくなりました。
無料プランだと制限時間もあるようなので、今回はローカル環境で動かすことを目標にしています。
1.tacotron2を動かす環境ではPythonは3.6を指定する
2023年現在の最新のtensorflowはPython3.7以上じゃないと動きません。
本当なら3.7を使いたいところですが、ネットにある情報はどれも古く、Python3.6を使ったものばかりでした。
なので今回は安牌(になっているかどうかはわかりませんが)をとってPython3.6系を使って、tensorflowも1.0系を使います。(最新はtensorflow2.0系)
その代わり推論用、前処理用の環境にはPython3.7を使っています。
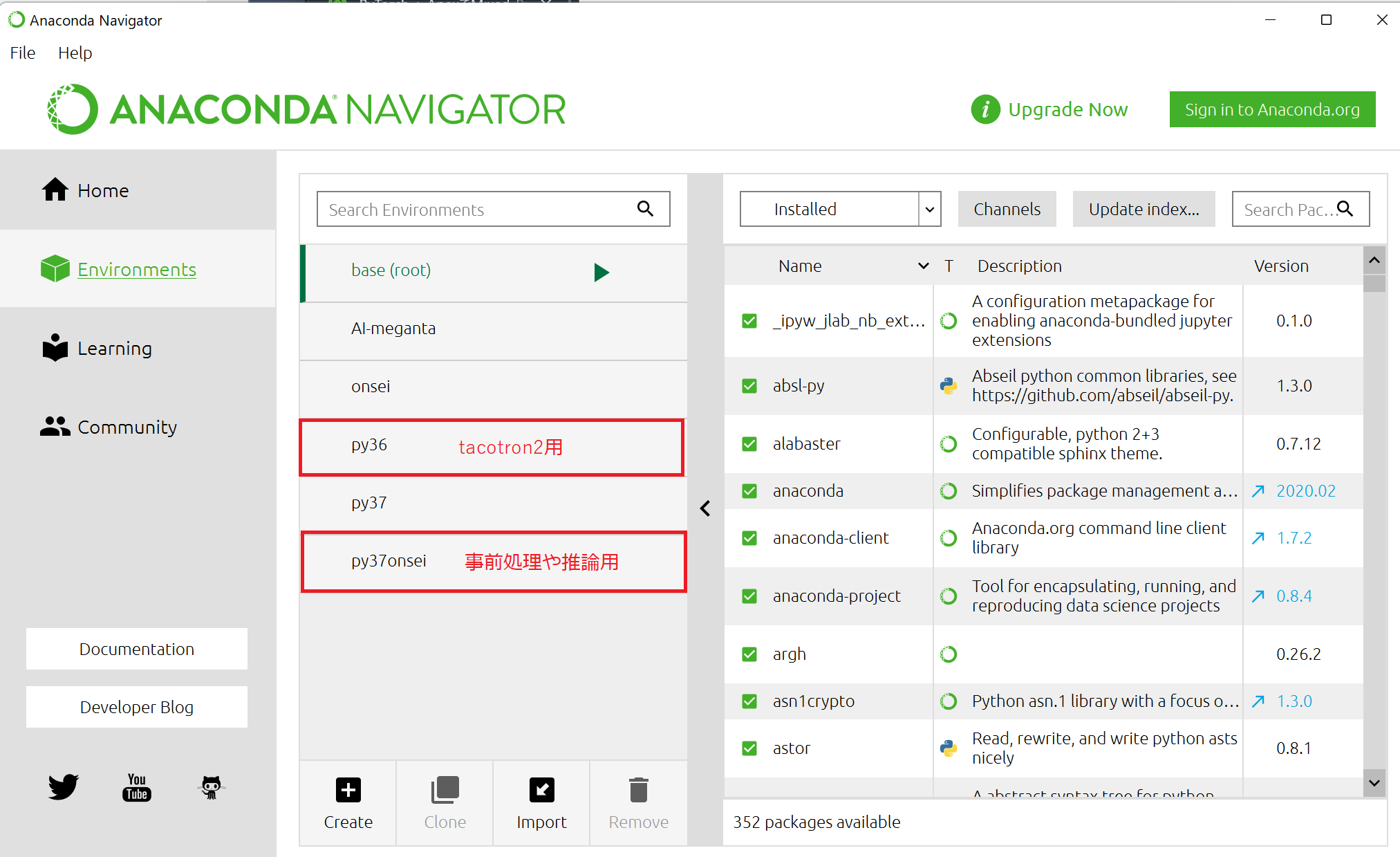
condaを使うべきか、pipを使うべきか
個人的にはpipを使うべきだと思っています。なので基本はpipで解説を進めていきます。
condaのほうがいいという話は聞いていますし、condaとpipでバッティングする話も聞いてはいますが、今のところ混在したことによる不都合は起きていません。
それでいうと、私はpipのみを使うようにしています。condaを使うのであればpipを使わず、condaのみで完結させるべきだとは思います。
2.「tensorflow1.15.5」のインストール(Python3.6環境)
pip install tensorflow==1.15.5不随してインストールされるライブラリ
Successfully installed
absl-py-1.3.0
astor-0.8.1
gast-0.2.2
google-pasta-0.2.0
grpcio-1.48.2
h5py-2.10.0
keras-applications-1.0.8
keras-preprocessing-1.1.2
numpy-1.18.5
opt-einsum-3.3.0
protobuf-3.19.6
six-1.16.0
tensorboard-1.15.0
tensorflow-1.15.5
tensorflow-estimator-1.15.1
termcolor-1.1.0
wrapt-1.14.13.「pytorch 1.6」のインストール
続いてpytorch1.6をインストールします。
pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html不随してインストールされるライブラリ
Successfully installed
future-0.18.2
pillow-8.4.0
torch-1.6.0+cu101
torchvision-0.7.0+cu1014.NVIDIA/tacotoron2をcloneして依存パッケージをインストール
https://github.com/NVIDIA/tacotron2
# NVIDIA/tacotron2のインストール
!git clone https://github.com/NVIDIA/tacotron2.git
%cd tacotron2
!git submodule init; git submodule updaterequirement.txtを編集する必要がありそう
tacotron2のrequirement.txt通りにインストールをするとバージョン差異による実行エラーが吐かれました。
いろいろ試した結果以下のような修正をおこなってからrequirement.txtを実行したほうがいいかもしれません。
matplotlib==2.1.0
#tensorflow==1.15.2 15系の最新バージョンでいいのでは、どっちでもいいかも
tensorflow==1.15.5
#numpy==1.13.3
numpy==1.18
inflect==0.2.5
#librosa==0.6.0
librosa==0.5.1
#scipy==1.0.0
scipy==1.4.0
Unidecode==1.0.22
#pillow Python3.7以上じゃないと最新盤は動かないので下げる
pillow==8.4.0修正が必要そうな部分はtensorflowとnumpyとlibrosaとscipyとpillowです。
最新版をインストールするとPython3.7系じゃないと動かないと言われたり、classがないと言われたり、コードが動かないため注意です。
5.apexをインストール
tacotron2を動かすにはNVIDIA/apexというライブラリをインストールする必要があります。
# Apexのインストール
!git clone https://github.com/NVIDIA/apex
%cd apex
!pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./pipインストールをする際「Unidecodeがない」というエラーが出る可能性があります。そのため先にUnidecodeをインストールしておくといいです。
pip install Unidecode==1.0.22apexをインストールする際、Windowsではこの段階でエラーが出る場合があります。
以下の記事を参考にすると治る可能性があります。
【Python】機械学習で使う「apex」がインストールできないときの対処方法(Windows)
インストールが成功したら、pip install -r requirements.txt も実行しておきますが、このreiquirements.txtもバージョン周りでコンフリクトが起きたりすると思います。
インストールされるライブラリは以下の通り。
Successfully installed
PyYAML-6.0
atomicwrites-1.4.1
attrs-22.2.0
colorama-0.4.5
cxxfilt-0.3.0
importlib-metadata-4.8.3
importlib-resources-5.4.0
iniconfig-1.1.1
pluggy-1.0.0
py-1.11.0
pytest-7.0.1
tomli-1.2.3
tqdm-4.64.1
typing-extensions-4.1.1
zipp-3.6.0最終的なフォルダ階層
以下がtacotron2を実行する際の階層構造です。
私の場合、すでにtrain.pyを実行した後の階層構造になっているので、完全に一致するかどうかはわかりませんが、ダウンロードしてきたファイルをどこに配置するのかなどは参考になると思います。
tacotron2:.
│ .gitmodules
│ audio_processing.py
│ data_utils.py
│ demo.wav
│ distributed.py
│ Dockerfile
│ hparams.py
│ inference.ipynb
│ layers.py
│ LICENSE
│ logger.py
│ loss_function.py
│ loss_scaler.py
│ model.py
│ multiproc.py
│ my_inference.ipynb
│ plotting_utils.py
│ README.md
│ requirements.txt
│ stft.py
│ tacotron2_statedict.pt
│ tensorboard.png
│ train.py
│ utils.py
│ waveglow_256channels_universal_v5.pt
│
├───filelists
│ ljs_audio_text_test_filelist.txt
│ ljs_audio_text_train_filelist.txt
│ ljs_audio_text_val_filelist.txt
│ transcript.txt
│ transcript_train.txt
│ transcript_val.txt
│
├───meian
│ meian_0000.wav
│ meian_0001.wav
│ meian_0002.wav
│ meian_0003.wav
│ meian_0004.wav
~~~~~~~~
│ meian_6838.wav
│ meian_6839.wav
│ meian_6840.wav
├───text
│ │ cleaners.py
│ │ cmudict.py
│ │ LICENSE
│ │ numbers.py
│ │ symbols.py
│ │ __init__.py
│ │
│ └───__pycache__
│ cleaners.cpython-36.pyc
│ cleaners.cpython-37.pyc
│ cmudict.cpython-36.pyc
│ cmudict.cpython-37.pyc
│ numbers.cpython-36.pyc
│ numbers.cpython-37.pyc
│ symbols.cpython-36.pyc
│ symbols.cpython-37.pyc
│ __init__.cpython-36.pyc
│ __init__.cpython-37.pyc
│
├───waveglow
│ │ .gitmodules
│ │ config.json
│ │ convert_model.py
│ │ denoiser.py
│ │ distributed.py
│ │ glow.py
│ │ glow_old.py
│ │ inference.py
│ │ LICENSE
│ │ mel2samp.py
│ │ README.md
│ │ requirements.txt
│ │ train.py
│ │ waveglow_logo.png
│ │
│ ├───tacotron2
│ └───__pycache__
│ denoiser.cpython-37.pyc
│ glow.cpython-37.pyc
│
└───__pycache__
audio_processing.cpython-36.pyc
audio_processing.cpython-37.pyc
data_utils.cpython-36.pyc
data_utils.cpython-37.pyc
distributed.cpython-36.pyc
distributed.cpython-37.pyc
hparams.cpython-36.pyc
hparams.cpython-37.pyc
layers.cpython-36.pyc
layers.cpython-37.pyc
logger.cpython-36.pyc
logger.cpython-37.pyc
loss_function.cpython-36.pyc
loss_function.cpython-37.pyc
model.cpython-36.pyc
model.cpython-37.pyc
plotting_utils.cpython-36.pyc
plotting_utils.cpython-37.pyc
stft.cpython-36.pyc
stft.cpython-37.pyc
train.cpython-37.pyc
utils.cpython-36.pyc
utils.cpython-37.pyctacotron2の学習の実行(train.py)
python train.py --output_directory=outdir --log_directory=logdir -c tacotron2_statedict.pt --warm_startWARNING:tensorflow:
The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
* https://github.com/tensorflow/io (for I/O related ops)
If you depend on functionality not listed there, please file an issue.
FP16 Run: False
Dynamic Loss Scaling: True
Distributed Run: False
cuDNN Enabled: True
cuDNN Benchmark: False
Warm starting model from checkpoint 'tacotron2_statedict.pt'
Epoch: 0
Train loss 0 4.530630 Grad Norm 106.327721 4.36s/it
Validation loss 0: 74.075213
Saving model and optimizer state at iteration 0 to outdir/checkpoint_0
Train loss 1 1.618356 Grad Norm 14.370405 3.57s/it
Train loss 2 3.936485 Grad Norm 68.261269 3.69s/it
Train loss 3 2.413089 Grad Norm 33.520912 3.78s/it
Train loss 4 1.628413 Grad Norm 13.512403 3.56s/it
:contribモジュールがTensorFlow2.0に含まれていないというエラーが出ますが、プログラム自体は実行されます。
このtrain.pyは何回で終わるというものではありません。
止めない限り実行されます。
私の場合、一回の学習に約2秒~3秒ほどかかりました。
丸々1日回した結果、31000回学習させたファイルが出来ました。
学習結果のファイルはoutdirというファイルに1000回ごとに自動で生成されていきます。
推論の際に音声を生成してみましたが、4000回学習させたものと30000回学習させたもので違いがほとんどなかったため、1万回くらいで止めてもいいかもしれません。
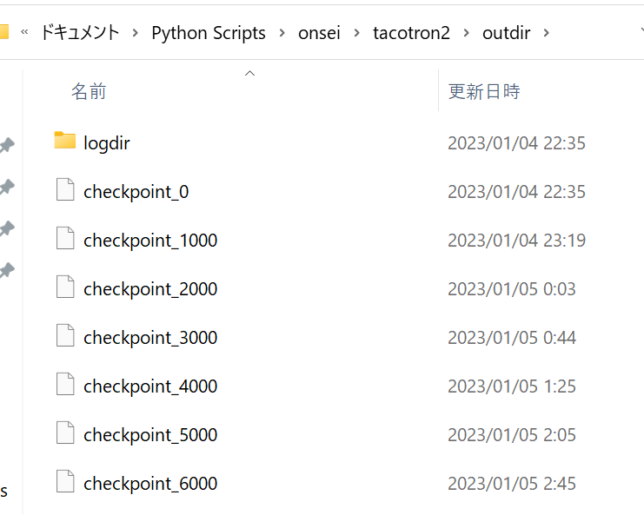
tacotron2が動いたときの最終的なpip list
tacotron2のtrain.pyを実行するときにパッケージのコンフリクトや、バージョンが低い、もしくは高いことによるプログラムのエラーが頻発しました。
すべて解消してtrainingができるようになるのに二日かかったわけですが・・・。
色々ライブラリのバージョンを上げたり下げたりしたのですが、すべてをメモしているわけではなかったので、最終的にtacotron2が動いたときの「pip list」を掲載しておきます。
以下を参考にライブラリのバージョンを確認してみてください。
(py36) C:\Users\○○>pip list
Package Version
-------------------- -----------
absl-py 0.15.0
apex 0.1
astor 0.8.1
atomicwrites 1.4.1
attrs 22.2.0
audioread 3.0.0
cachetools 4.2.4
certifi 2021.5.30
charset-normalizer 2.0.12
colorama 0.4.5
cxxfilt 0.3.0
cycler 0.11.0
dataclasses 0.8
decorator 5.1.1
future 0.18.2
gast 0.2.2
google-auth 1.35.0
google-auth-oauthlib 0.4.6
google-pasta 0.2.0
grpcio 1.48.2
h5py 2.10.0
idna 3.4
importlib-metadata 4.8.3
importlib-resources 5.4.0
inflect 0.2.5
iniconfig 1.1.1
joblib 1.1.1
Keras-Applications 1.0.8
Keras-Preprocessing 1.1.2
librosa 0.6.2
llvmlite 0.31.0
Markdown 3.3.4
matplotlib 2.1.0
mkl-fft 1.3.0
mkl-random 1.1.1
mkl-service 2.3.0
numba 0.48.0
numpy 1.18.0
oauthlib 3.2.2
opt-einsum 3.3.0
packaging 21.3
Pillow 8.4.0
pip 21.2.2
pluggy 1.0.0
protobuf 3.19.6
py 1.11.0
pyasn1 0.4.8
pyasn1-modules 0.2.8
pyparsing 3.0.9
pyreadline 2.1
pytest 7.0.1
python-dateutil 2.8.2
pytz 2022.7
PyYAML 6.0
requests 2.27.1
requests-oauthlib 1.3.1
resampy 0.3.1
rsa 4.9
scikit-learn 0.24.2
scipy 1.5.3
setuptools 58.0.4
six 1.16.0
tensorboard 1.15.0
tensorflow 1.15.0
tensorflow-estimator 1.15.1
termcolor 1.1.0
threadpoolctl 3.1.0
tomli 1.2.3
torch 1.6.0+cu101
torchvision 0.7.0+cu101
tqdm 4.64.1
typing_extensions 4.1.1
Unidecode 1.0.22
urllib3 1.26.13
webencodings 0.5.1
Werkzeug 0.16.1
wheel 0.37.1
wincertstore 0.2
wrapt 1.14.1
zipp 3.6.0遭遇したエラーの一覧と対処に関するメモ
書き出してみると、train.py自体を実行するまでにやることは少ないかもしれませんが、学習を実行するまでにかなりたくさんのエラーに遭遇しました。
原因として考えられることの多くはバージョンの違いによるものが多いと思います。
一つ一つエラー潰しをしていくしかありませんが、どうしても動かない場合は、仮想環境を削除して作り直すのも手だと思います。
私は実行までに4回仮想環境を作り直しました。
エラー:No module named 'tensorboard' もしくは'tensorflow'
pipではなくcondaしたら通りました。
conda install -c conda-forge tensorboard==1.15.0けど、その後pipをごちゃごちゃやってたらまたno module namedが出てきました。
condaとpipの混在によるライブラリの保存場所問題が起きていると思います。
conda uninstall後、再度conda installをするとエラーが消えた。
これ毎回やらないといけないのか・・・?
guvectorize() missing 1 required positional argument: 'signature'
Traceback (most recent call last):
File "train.py", line 13, in <module>
from model import Tacotron2
File "C:\Users\sena\Documents\Python Scripts\onsei\tacotron2\model.py", line 6, in <module>
from layers import ConvNorm, LinearNorm
File "C:\Users\sena\Documents\Python Scripts\onsei\tacotron2\layers.py", line 2, in <module>
from librosa.filters import mel as librosa_mel_fn
File "C:\Users\sena\anaconda3\envs\py36\lib\site-packages\librosa\__init__.py", line 12, in <module>
from . import core
File "C:\Users\sena\anaconda3\envs\py36\lib\site-packages\librosa\core\__init__.py", line 110, in <module>
from .audio import * # pylint: disable=wildcard-import
File "C:\Users\sena\anaconda3\envs\py36\lib\site-packages\librosa\core\audio.py", line 12, in <module>
import resampy
File "C:\Users\sena\anaconda3\envs\py36\lib\site-packages\resampy\__init__.py", line 7, in <module>
from .core import *
File "C:\Users\sena\anaconda3\envs\py36\lib\site-packages\resampy\core.py", line 11, in <module>
from .interpn import resample_f_s, resample_f_p
File "C:\Users\sena\anaconda3\envs\py36\lib\site-packages\resampy\interpn.py", line 75, in <module>
nopython=True,
TypeError: guvectorize() missing 1 required positional argument: 'signature'エラー:HDF5 library version mismatched error
Warning! ***HDF5 library version mismatched error***
The HDF5 header files used to compile this application do not match
the version used by the HDF5 library to which this application is linked.
Data corruption or segmentation faults may occur if the application continues.
This can happen when an application was compiled by one version of HDF5 but
linked with a different version of static or shared HDF5 library.
You should recompile the application or check your shared library related
settings such as 'LD_LIBRARY_PATH'.
You can, at your own risk, disable this warning by setting the environment
variable 'HDF5_DISABLE_VERSION_CHECK' to a value of '1'.
Setting it to 2 or higher will suppress the warning messages totally.
Headers are 1.10.6, library is 1.10.5HDF5というライブラリのバージョンが違うというエラー。
pipでhdf5しようと思って実行しましたが、どうやらcondaじゃないとインストールできないもののようなので、こちらはcondaでインストール。
そうするとエラーが消えました。
conda install -c conda-forge hdf5=1.10.5参考:HDF5バージョンミスマッチエラー ***HDF5 library version mismatched error***
エラー:no module named typing_extensions
pipして解消。
pip install typing-extensionsエラー:future feature annotations is not defined
pillowのバージョンを8.4に落とすと以下が解決されます。
Python3.7じゃないと使えない構文が使われているようです。
future feature annotations is not defined今回はrequirements.txtを書き換えているので、発生しないかもしれません。
エラー:'CacheManager' object has no attribute 'cachedir'
librosaライブラリでエラーが起きていますが、原因はlibrosaではなくjoblibというライブラリのバージョンが高いことが原因のようです。
なのでjoblibのバージョンを下げると解決しました。
pip install joblib==0.17.0joblib1.0系だとダメのようです。
エラー:No module named 'numba.decorators'
numbaのバージョンをダウングレードすることで解消しました。
今回のエラーはダウングレードで解決できることが割と多いです。
pip install numba==0.49.1エラー:guvectorize() missing 1 required positional argument: 'signature'
'resampy'のversion 0.4.2から0.3.1にダウングレードすることで解消されました。
pip install resampy==0.3.1エラー:No module named 'numpy.testing.decorators'
scipyのバージョンが古いために発生するエラーのようです。(requirements.txtの通りなんだけど・・・)
1.0.0から1.5.4(現在の最新バージョン)まで引き上げることで解消されました。
pip install -U scipymodule 'tensorflow' has no attribute 'contrib'
tensorflow2.0系をインストールしてしまうと、このようなエラーが発生します。
tensorflow1.0系に下げることで解消されるかもしれませんが、そうするとPython3.7以上の場合対応していないとエラーがでます。
そのため仮想環境をPython3.6系でtensorflow1.0系をいれる専用のものを用意したほうがいいと結論づけました。
エラー:RuntimeError: CUDA out of memory. tacotron
GPUのメモリ上限を超えたバッチサイズが設定されていることが原因です。
これを回避するためにはhparam.pyのbatch_sizeを変更します。
batch_size=20,#デフォルトで64 https://github.com/a8568730/Tacotron-2/issues/8Downgrade the protobuf package to 3.20.x or lower
protobugというライブラリを3.2系までダウングレードすることで解消します。
pip install protobuf==3.20.*https://stackoverflow.com/questions/72899948/how-to-downgrade-protobuf
推論
学習結果がどのような結果になっているのかの検証には「tacotron2/inference.ipynb」ファイルを参考にします。
私の場合「my_inference.ipynb」というファイルを新規で作ってそちらで推論していきます。
上述の通り、tacotron2を動かした環境とは別の仮想環境を用意します。
今回はPython3.7が入っている環境を用意しました。
ライブラリをインポートして matplotlib をセットアップする
import matplotlib
%matplotlib inline
import matplotlib.pylab as plt
import IPython.display as ipd
import sys
sys.path.append('waveglow/')
import numpy as np
import torch
from hparams import create_hparams
from model import Tacotron2
from layers import TacotronSTFT, STFT
from audio_processing import griffin_lim
from train import load_model
from text import text_to_sequence
from denoiser import Denoisertacotron2/inference.ipynbと同じです。必要なものは都度pipでインストールしてください。
def plot_data(data, figsize=(16, 4)):
fig, axes = plt.subplots(1, len(data), figsize=figsize)
for i in range(len(data)):
axes[i].imshow(data[i], aspect='auto', origin='bottom',
interpolation='none')hparamsのセットアップ
hparams = create_hparams()
hparams.sampling_rate = 22050チェックポイントからモデルをロード
checkpoint_path = "tacotron2_statedict.pt"
model = load_model(hparams)
model.load_state_dict(torch.load(checkpoint_path)['state_dict'])
_ = model.cuda().eval().half()mel2audio 合成とノイズ除去用に WaveGlow をロードする
waveglow_path = 'waveglow_256channels_universal_v5.pt'
waveglow = torch.load(waveglow_path)['model']
waveglow.cuda().eval().half()
for k in waveglow.convinv:
k.float()
denoiser = Denoiser(waveglow)読ませるテキストの準備
text = "konnichiwa"
sequence = np.array(text_to_sequence(text, ['basic_cleaners']))[None, :]
sequence = torch.autograd.Variable(
torch.from_numpy(sequence)).cuda().long()テキストを読ませて音声ファイルとして出力する
mel_outputs, mel_outputs_postnet, _, alignments = model.inference(sequence)
with torch.no_grad():
audio = waveglow.infer(mel_outputs_postnet, sigma=0.666)
ipd.Audio(audio[0].data.cpu().numpy(), rate=hparams.sampling_rate)実際に出力された音声ファイルはこのようになります。
「こんにちは」という短い文章を読ませているのですが、なんだか余分に音声が続いています。
なぜなのかという検討は棚上げしておいて、とにかくtacotron2で学習させた音声を出力させることに成功しました。
まとめ
いまさらtacotron2かよ、と思う人もいるかもしれませんが、音声合成をローカルでやっている人も少ないかと思い、何かの参考になればとして書き残しておきます。
今回はあくまで英語を学習させただけなので、今後は日本語、そして自分で作りたい音声を学習させていきたいと思います。
発生したエラーは書き残したもの以上にありました。
躓きそうだなと思った奴だけピックアップしていますが、もしもエラーが発生した際は、TwitterのDM、もしくはこのブログの問い合わせフォームに送ってもらえれば助言できるかもしれません。
以上です。
お疲れ様でした。
参考記事
https://qiita.com/marukun_/items/8815385ca41ad007ee48
https://qiita.com/t-ae/items/773e92a2176795193ad1
https://qiita.com/sujoyu/items/8b786b35d20f497507c5
https://note.com/npaka/n/n2a91c3ca9f34
https://heartstat.net/2022/04/10/python_speech-synthesis_myvoice/