【期待度ランキング】2019年夏アニメの期待度ランキングをプログラミングで自動生成する【Python】
最近ではほとんどアニメを見る機会が減ってしまいました。
子供のころは毎日アニメを見ていました。宮崎駿のジブリ映画や庵野秀明のエヴァンゲリオンなどの名作に加え、2000年代の深夜アニメも一通り見てきました。
高畑勲が死んでしまったのがとても悲しいです。ハイジや火垂るの墓などは子供心ながら、強烈なインパクトを与えました。本当にすごいアニメは人の心に残るものだと思っています。
そんななか、アニメは量産され続けています。(アニメーターが安い賃金でアニメを量産する体制は、もとを辿れば手塚治虫が始めたことです。)
たくさんアニメが作られれば「面白いアニメ」「つまらないアニメ」がどうしても生まれてしまいます。ですから、どうせ見るなら面白いアニメを見たいと思うのは普通のことでしょう。
そんな時のためにあるのがランキングサイトです。
アニメのランキングがアフィサイトだらけの現状
アニメのランキングサイトは大量にあります。
一昔前は「ちゃんとアニメを見た人が作ったランキング」があったように思います。
しかし最近ではどう考えても見てもいないとわかるような感想が書かれていたり、本当に面白いアニメが紹介されていないランキングサイトばかりといいった印象を受けます。
あとSEOを意識して、トップ100などというもはやランキングの体をなしていないページも数多あります。

こういったページが作成されるのはいいですが、個人的には1位がページの一番下にあるのが嫌です。
100位から1位まで情報を垂れ流した上にとんでもく長いページをスクロールさせられることになります。
実際100個のアニメを紹介したページが上位にきてしまうのですから、検索エンジン側にも問題があるように思います。

なぜランキング型アフィサイトが乱立するか
理由はもちろんお金です。
アフィリエイトでは商品を紹介して、紹介したものが買われてはじめて収益が発生します。
基本的に1記事1商材でページを作成していくので、手間が非常にかかります。
しかしランキングサイトにしてしまえば、一度に多くの商品を紹介することができます。そのためランキング型のアフィサイトが乱立されていまいます。


ランキングサイトの問題点は恣意的なものになってしまうこと
ここでランキング型のアフィリエイトを批判しているわけではもちろんありません。
私もブログ内に広告を貼っていますし、サイト運営者にお金が入るのはいい事で。
これは普遍的な問題ですが、ランキングサイトはどうしても恣意的になりやすいという問題点を持っています。
ランキングサイトの問題点は以下のとおりです。
- ランキングの付け方が個人の趣味嗜好に偏ってしまう。
- トップ100など無作為に抽出されたページが作られてしまう
- ランクインしている作品の説明にはあらすじしか書かれておらず、なぜそのアニメがその順位なのか書いていない。
- どんな基準ででランキング付けされているのかわからない
「アニメ ランキング」で検索した時に上位にくるページはトップ100のランキングがでてきますが、あまりにも内容が薄く、何も感じない虚無なページになっています。

そのページのコメント欄を見ても「なぜこのアニメがランキングにはいっていないのか」「ランキング作成者の好みが見えない」「u-nextで見れるアニメを順番に説明しただけ」というコメントが寄せられていました。
まったくそのとおりだと思います。
しかしもしかしたらこのページの作成者が本当にランクインしたアニメを見てランク付けした可能性もあります。
何が言いたいかというと、誰がランキングを作っても不満は出るし、恣意的になってしまうということです。
どちらにしろ順位付けするわけなので、全員が幸せになれるものではないでしょう。
統計的にアニメの期待度や面白さをランキング付けできないか
ランキングが持つ問題を解決するためにはこのようなことが考えられます。
- ランキングの根拠を記載する
- ランキングを統計的に算出する
個人的に出したランキングには必ず問題があります。
であれば、ロジックでランキングを出すしかありません。
趣味嗜好というものを完全に数値化できるかというのは難しい問題です。
ですが今回試みとして、Pythonを使った感情分析をおこない、感情でランキングが作れないかやってみようと思います。
Pythonでツイートを取得して、感情分析をするものを作ってみる
さっそくPython使ってプログラミングしていきます。
まずは必要な機能を洗い出します。
- 感情分析をするためtwitterに投げるクエリを決める
- twitterAPIでツイートを取得する
- 取得したツイートの本文だけを抽出する
- 本文に対して感情分析をおこなう
実現のためには大きく4つの機能が必要のようです。
一つ一つ方法を解説していきます。
感情分析をするためtwitterに投げるクエリを決める

まずはツイッターでどういう検索をすればいいのかを考えます。
クエリとはキーワード検索に入れる内容です。
例えば「荒ぶる季節の乙女どもよ。」についての評判を検索したいと思います。
検索してみた結果が以下の画像です。

アニメ名をそのままで検索するとこうした別ページへの誘導をしているツイートも少なからず含まれます。こうしたつぶやきはアニメに対する純粋な思いがかかれていないため、今回は除外します。
それからbotの存在もノイズになってしまいます。

機械を使って自動でつぶやかせるいわゆるbot。
これもアニメへの感情を測定するのに邪魔になるため、今回除外します。
botを使った定期ツイート
それから自らつぶやかずに、他人が呟いたことを再度つぶやくリツイート機能があります。
今回こちらも除外対象とします。同じ意見が重複して集計されるのは避けるべきです。
合わせてリプライ機能で返答されたツイートも対象外とします。
長くなりましたが、今回ツイッターで検索するクエリは以下のようになりました。
検索キーワード ' -"bot" -"定期" OR @ecokfeognokaos exclude:retweets -filter:links -filter:replies -source:twittbot.net'
ちなみに@ecokfeognokaosというのは適当な文字列です。
ツイッターの検索機能はつぶやきだけでなく、ユーザー名も検索対象に含めてしまいます。それを回避するために、あえて存在しないユーザー名を指定してあげています。
クエリの設定のまとめは以下のとおりです。
- 外部リンクを含むツイートを除外
- botを除外
- 定期的なつぶやきを除外
- リツイートを除外
- リプライを除外
Twitter apiでツイートの本文を取得する。
ツイッターに投げるクエリは決まりました。
次はtwitter apiでツイートを取得する部分を作成していきます。
Twitter apiを使用するためにはアカウントの申請をおこなう必要があります。

こちらのqiitaの記事を参考にさせていただきました。
こちらでは登録方法については割愛させていただきます。
他のサイトも見ましたが、多くの方が方法をまとめられていたので助かりました。
手順に従いkeyと手に入れられたらさっそくプログラムを書いて実行します。
apiを叩くと多くの情報を得ることができます。
- 投稿日
- 投稿者情報
- 本文
- ツイートID
- このツイートがリツイートされた数
- どの言語で書かれているか
- etc
たくさん情報がありすぎて目移りしてしまいそうですが、ここではテキスト情報のみ扱います。
keyを設定してapiを実際に叩いてみます。

無事に取得できました。
ちなみにtwitter apiの制限は最近になってかなり制限が強くなりました。大量にツイートを取得するのであれば、待機処理を追記することをおすすめします。
(今回はサンプルが少なかったので待機処理は実装していません)
ツイートに感情分析をかけ、ランキングを作成する
やっと感情分析について進められる環境が整いました。
ここからが一番メインになるのですが・・・。ここまで設定に3日ほどかけてしまっています。
まずどうやって感情分析をするか考えなくてはいけません。
Word2vecを使う&コーパスを手に入れる
調べてみると「word2vec」という技術が使えそうということがわかりました。
はじめてword2vecを使いましたが、以下のサイトが非常に参考になりました。
すごく簡単にいうと、word2vecとは単語をベクトル化することです。
単語同士の意味の「近さ」を計算して、数値化することができます。
難しく聞こえますが、よく引き合いに出される例に王様の計算式があります。
王様-男+女=女王
こういった計算は人だけがおこなえるわけではありません。
word2vecを使えばコンピュータにもおこなうことができるようになるようです。
つまりツイートを単語で分割し、人の感情を表す単語と比較していけば、自然とその文章が持つ感情を計算できるようになるということです。
面白いですね。
word2vecを使うためには学習データが必要です。
学習データを自分で作成してもよかったですが、学習済みのデータを公開している組織などありましたので、今回はそちらを使わせていただきました。
東北大学 乾・岡崎研究室のモデルを使用させていただきます。
こういった学習データをコーパスと呼びます。
コーパスは用意できました。
Mecabで形態素解析をする
次にテキストを単語ごとに区切る必要がありますが、これはMecabを使います。

mecabは形態素解析をするためのライブラリです。
形態素解析をしようと思ったら一度は名前を聞くことになるでしょう。
そのため使い方については多くの情報がネットに転がっておりますので、興味がありましたら調べてみてください。
プルチックの感情の輪から感情を表現する単語を選定する
感情といっても多くの感情があります。
どれくらいの数があるのか調べてみました。

最近になって驚きの論文が出されていたようです。
なんと人間の感情は合計で2185個もあるということでした。
ちょっと数が多すぎますね。
でもその2185個の感情でランキングを作ったらまた面白いかもしれません。
とはいえ、今回はその中でももっともポピュラーな感情をチョイスすることにします。
プルチックの感情の輪に出てくる人間の基本的8つの感情を使用します。

つまり「喜び、信頼、不安、驚き、悲しみ、嫌悪、怒り、期待」の8つです。

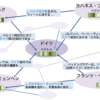
上図が実際に文章を単語に分け感情分析する方法です。
イメージでは「面白い」という単語だけに絞って計算していますが、実際はもっと多くの単語を使っています。
これらによって得られたデータを平均でとり、最も期待の感情が高まっているアニメを選んでみます。
さて結果はどうなるでしょうか。
感情分析による2019年夏アニメ期待度ランキング
| 順位 | アニメ名 | 期待度数 |
| 1位 | Dr.STONE | 0.236 |
| 2位 | 彼方のアストラ | 0.233 |
| 3位 | ソウナンですか? | 0.224 |
| 4位 | ダンベル何キロ持てる? | 0.221 |
| 5位 | ナカノヒトゲノム【実況中】 | 0.216 |
| 6位 | かつて神だった獣たちへ | 0.215 |
| 7位 | あんさんぶるスターズ! | 0.210 |
| 8位 | ありふれた職業で世界最強 | 0.210 |
| 9位 | 炎炎ノ消防隊 | 0.209 |
| 10位 | ヴィンランド・サガ | 0.203 |
| 11位 | 戦姫絶唱シンフォギアXV | 0.199 |
| 12位 | 荒ぶる季節の乙女どもよ。 | 0.194 |
| 13位 | ロード・エルメロイⅡ世の事件簿 -魔眼蒐集列車 Grace note- | 0.194 |
ついに期待度ランキングを出す事ができました。
1位が「ドクターストーン」、2位が「彼方のアストラ」、3位が「ソウナンですか」という結果となっています。
実際にやってみてもちょっと信憑性がありそうだなぁと我ながら思っています。
特にドクターストーンはジャンプで唯一読んでいる漫画だったので、結果1位となり少しうれしい気持ちになりました。



まとめ
今回はツイッターのつぶやきを使用して2019年夏アニメの期待度ランキングを算出しました。
個人的には非常にいい結果になったのではないかと思っています。
公開はしていませんが、2019年夏アニメ不安度ランキングみたいなものも出しています。
機会があれば公開したいと思っています。
長くなりましたが以上になります。
なにかwebサービスとしてランキングサイトを開いてもいいかもしれないと思いました。
ここまで読んでいただきありがとうございます。